My Role
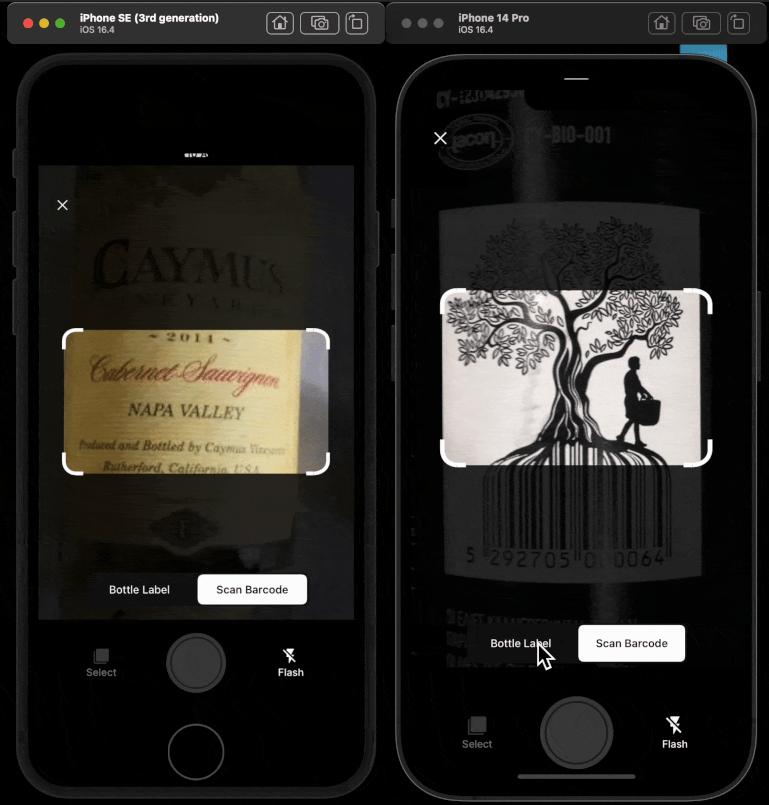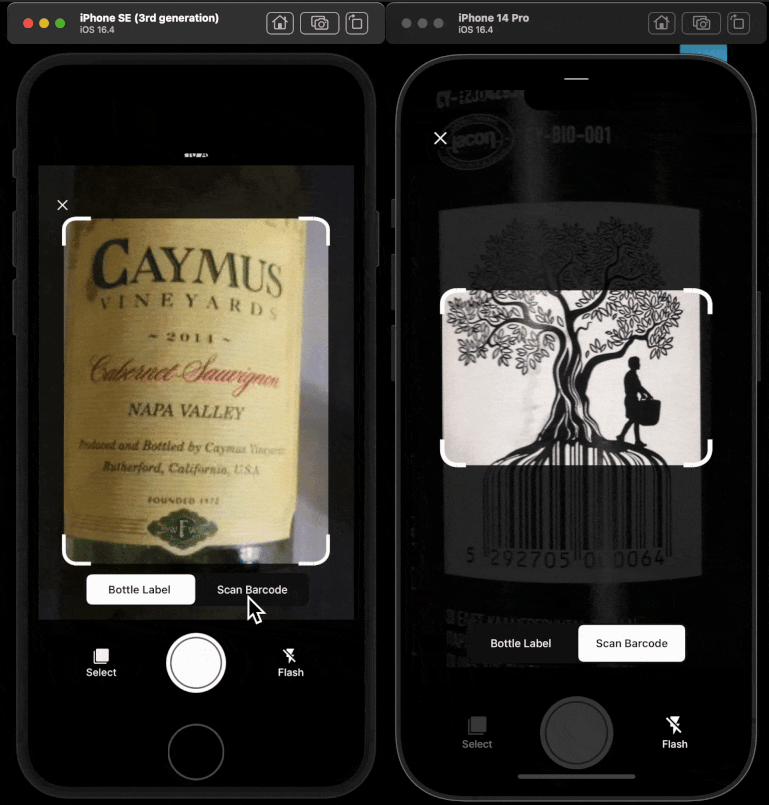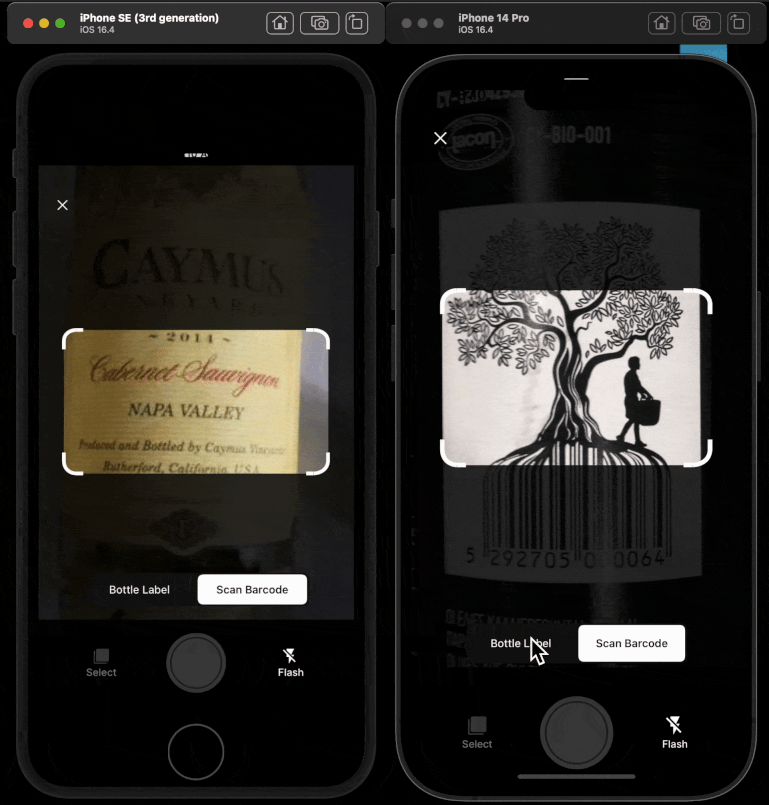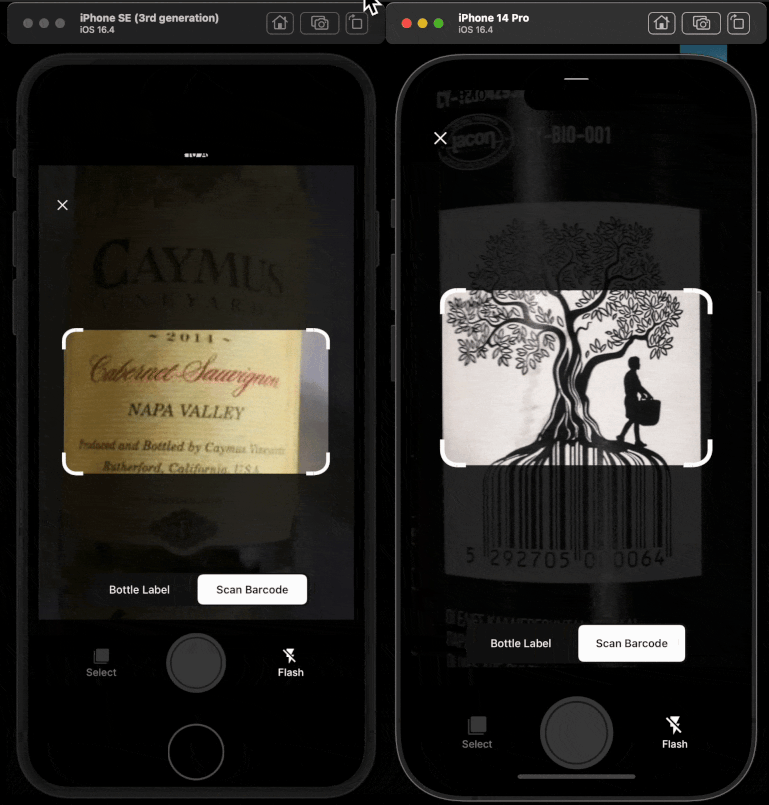
I worked across the stack to turn CellarChat from concept into a production AI surface during my August 2023 to July 2025 engagement. I led and implemented core RAG architecture, agentic workflows, OpenAPI tool integration, and LLM observability. I designed the golden-set methodology, built CI/CD-connected evaluations, and shipped the React Native evaluations dashboard that graphed quantitative and qualitative quality over time for product and executive stakeholders. CellarTracker is a wine cellar management platform where members track inventory, decide what to open, monitor drinking windows, and learn from community tasting notes. The user problem sounds simple, but the data is not. Wine data spans structured records like bottle counts, vintages, storage locations, and dates, plus unstructured content like tasting notes, preferences, and free-form prompts; good answers depend on both data types together, and the assistant has to reason in product context so it knows what the member owns, where bottles are stored, and what is actionable right now. At that scale, "ship and hope" is not viable. I built the evaluations dashboard so I could measure whether the assistant stayed grounded as data and models changed. I contributed to the Python backend that powered AI orchestration and retrieval flows. On the product side, I integrated the AI system into TypeScript frontend experiences and React Native mobile surfaces so the assistant was available where members already manage their collections. I treated this as a systems problem, not a prompt-only problem.
- RAG architecture and retrieval quality tuning for structured and unstructured wine data
- Agentic workflows with OpenAPI tool-calling and multi-step orchestration paths
- End-to-end ownership of LLM evals, observability, and the React Native evaluations dashboard used for release gating
- Golden-set design, SQL-backed quantitative scoring, LLM-as-judge qualitative rubrics, and CI/CD trend visualization
- Python backend delivery plus TypeScript and React Native product integration